Eduardo González De Viñasprehttps://eduvitoriatecnicomio.wordpress.comMi actividad profesional gira alrededor del mundo de los unos y los ceros. Puedo definirme como arquitecto software con una amplia experiencia de más de dos décadas diseñando soluciones informáticas para importantes empresas nacionales e internacionales.
En esta última parte de mi trayectoria profesional me he especializado en el liderazgo de equipos y la creación de las infraestructuras necesarias para que se lleven a cabo proyectos de desarrollo, grandes o pequeños, en las principales tecnologías JAVA, Javascript o .NET.
Cuando no estoy delante de una pantalla me encanta pasar tiempo con mi familia, mezclarme con el mundo que me rodea viajando en furgoneta, en bicicleta o como últimamente me gusta hacer, corriendo.
A veces necesito que mis sitios web funcionen sobre un canal HTTP seguro y no quiero, por falta de presupuesto o por falta de necesidad, que una CA (entidad certificadora de confianza) me firme un certificado.
Para estos casos, y usando OpenSSL, genero un certificado auto-firmado.
El certificado auto-firmado no sirve para garantizar la identidad de mi servidor, pero al menos me provee de un canal de comunicación seguro.
Esto suele ser un caso de uso bastante habitual en entornos de pruebas y/o de desarrollo.
[1er paso] Generar una solicitud de firma de certificado (CSR, Certificate Signing Request)
La solicitud de firma de certificado contiene la información del certificado junto con la clave pública, y es la información que se envía a las autoridades certificadoras (CAs) para que la firmen y generen el certificado de confianza.
Para generar la solicitud de firma CSR de un website que se llama techstrategydev.midominio.net, se ejecuta el siguiente comando:
$> openssl req -new -newkey rsa:2048 -nodes -keyout techstrategydev.midominio.net.key -out techstrategydev.midominio.net.csrGenerating a 2048 bit RSA private key.....+++...........................+++writing new private key to 'techstrategydev.midominio.net.key'-----You are about to be asked to enter information that will be incorporatedinto your certificate request.What you are about to enter is what is called a Distinguished Name or a DN.There are quite a few fields but you can leave some blankFor some fields there will be a default value,If you enter '.', the field will be left blank.-----Country Name (2 letter code) [AU]:ESState or Province Name (full name) [Some-State]:BizkaiaLocality Name (eg, city) []:BilbaoOrganization Name (eg, company) [Internet Widgits Pty Ltd]:EGV COMPANYOrganizational Unit Name (eg, section) []:ARQUITECTURACommon Name (e.g. server FQDN or YOUR name) []:techstrategydev.midominio.netEmail Address []:mi.email@midominio.netPlease enter the following 'extra' attributesto be sent with your certificate requestA challenge password []:xxxxxxxxxxxxAn optional company name []:
Esta ejecución debería generar dos ficheros:
El fichero *.key que es la clave privada que hay que guardar en un lugar seguro bajo siete candados. Este fichero está protegido por la contraseña que hemos introducido cuando nos ha pedido «A challenge password».
El fichero *.csr, que es la petición de firma de certificado que contiene la clave pública.
[2o paso (opcional)] Comprobar los datos introducidos en la solicitud de firma de certificado (CSR, Certificate Signing Request)
Se puede comprobar que la información que hemos introducido en la petición es correcta.
Se puede comprobar el «Subject» ejecutando el siguiente comando:
[3er paso] Auto-firmar la petición CSR y generar el certificado auto-firmado.
El fichero CSR es el que se envía a la entidad certificadora (CA) para que lo firme y nos devuelva el certificado firmado. En este caso, como ya hemos dicho, no vamos a enviarlo a ninguna CA si no que vamos a firmar nosotros la solicitud (CSR) usando la clave privada.
El parámetro -days indica el número de días en los que el certificado es válido. En este caso, al indicar 1095 días estamos diciendo que el certificado tiene una validez de 3 años (365×3).
La ejecución de este comando nos genera un fichero *.crt que contiene el certificado auto-firmado.
[4o paso (opcional)] Generar el certificado en formato PFX
La extensión PFX se utiliza en los servidores de Windows para los archivos que contienen tanto los archivos de clave pública (el archivo *.crt con el certificado auto-firmado) y la clave privada que corresponde a ese certificado (generado por el servidor cuando hemos generado la CSR en el 1er paso).
Para obtener el fichero PFX se ejecuta el siguiente comando:
Este comando nos solicitará una password para proteger la clave privada y tras esto nos genera un fichero *.pfx que ya podemos incluir en nuestro servidor windows, o como es mi caso en la nube de azure.
El manejo, desarrollo y configuración de los backend es el punto fuerte de mi carrera profesional, y debo reconocer que tengo un gran debe con el frontend.
Acabo de comenzar un proyecto en el que Angular 8 y PrimeNG van a ser mis grandes aliados para crear una interfaz de usuario web atractiva. Me ha llegado el momento, por tanto, de comenzar a escribir algunos posts relacionados con Javascript. El primero, como crear en mi MAC un entorno de desarrollo que me permita crear la web del futuro.
Requisitos.
Para desarrollar con Angular, es necesario tener:
Node.js – En versión 12.2.0 o superior.
Typescript – En versión 2.1 o superior.
Navegador – Recomendado utilizar Google Chrome, aunque Mozilla Firefox también funcionará bien.
Instalar Angular CLI
Instalar un IDE de desarrollo.
Instalar homebrew.
Para instalar los requisitos hay varias maneras de hacerlo, utilizando por ejemplo el instalador que te descargas del website correspondiente (p.e el instalador de node.js https://nodejs.org/es/download/) o utilizando Homebrew, un gestor de paquetes macOS para instalar aquellos paquetes que no se instalan desde la tienda de Apple.
Utilizar Homebrew permite instalar, desinstalar y actualizar de manera automática los paquetes que se vayan necesitando.
Para instalar homebrew hay que ejecutar desde un terminal lo siguiente:
Para comprobar que brew se ha instalado correctamente puedes ejecutar el comando brew con la opción –version. El resultado debería ser la versión instalada.
$brew --versionHomebrew 2.1.6Homebrew/homebrew-core (git revision ebe4; last commit 2019-06-16)
Homebrew habrá creado una estructura de directorios para manejar aquellas aplicaciones que se instalan utilizando la herramienta. Esto ordenará la instalación de esos paquetes y aplicaciones que no se instalan utilizando las herramientas de MAC.
Si ya tenías instalado brew, acuérdate de actualizarlo:
$brew update
Instalar Node.js
Instalaremos nodejs utilizando homebrew.
Instalaremos nodejs utilizando directamente el instalador del website de nodejs. La página de descargas es https://nodejs.org/es/download/.
Al terminar la instalación habrá dejado instalado el ejecutable node y el gestor de paquetes npm en el directorio ejecutable de usuario /usr/local/bin.
Para comprobar que nodejs está correctamente instalado puedes preguntar por las versiones tanto de node como de npm.
$ node -v
v10.16.0
$npm -version
6.9.0
Instalar Typescript
Para que angular funcione correctamente usaremos typescript 2.1 o superior. Para instalarlo usaremos el gestor de paquetes npm.
$ npm install -g typescript
Instalar Angular CLI
Angular CLI es la consola de cliente que se utiliza en angular para administrar la creación de aplicaciones.
$ npm install -g @angular/cli
Para probar que se ha instalado correctamente como siempre se puede consultar la versión instalada.
Existen tantos IDEs de desarrollo como estrellas en el firmamento. Quizás esto es una exageración, pero hay muchos. Mi recomendación es que instales uno con el que te sientas a gusto, y si no tienes preferencias, que instales Visual Studio Code de Microsoft. Gratis y continuamente mantenido.
Martin Fowler propone en su artículo “Microservices” una de las definiciones que más me gusta para describir qué son los microservicios:
La arquitectura basada en microservicios es una nueva manera de desarrollar aplicaciones como si fueran un conjunto de pequeños servicios, cada uno de ellos corriendo su propio proceso (servidor) y comunicándose entre si utilizando mecanismos de comunicación ligeros, normalmente protocolo HTTP.
Lo dice él y lo comparto yo, los microservicios son una nueva manera de diseñar aplicaciones que obliga a tener en cuenta el hecho de que cada funcionalidad es un servicio, cada uno con sus propios recursos, abandonando el consabido enfoque monolítico tradicional donde todas las funcionalidades forman parte de una único servicio.
Esta entrada abre una sucesión de artículos donde de manera básica quiero aproximarme al mundo de los microservicios utilizando diferentes aproximaciones; Spring Cloud, Play y vert.x.
Este primer artículo recorre el enfoque desde el punto de vista de Spring con Spring Cloud. Mi intención es implementar unos microservicios utilizando el ecosistema propuesto por Spring framework, a saber; Springfox, la implementación de Spring de la especificación Swagger para documentar la API REST, y Spring Cloud Netflix para ofrecer el microservicio y ponerlo a disposición de terceros a través del Service Registry de Netflix, Eureka.
El ejemplo.
El ejemplo elegido es una funcionalidad básica pero suficiente para permitir probar el desarrollo de microservicios a través de las soluciones elegidas, en esta entrada Spring Cloud.
La aplicación va a dar servicios a operaciones aritméticas ofreciendo dos microservicios, uno que realiza suma de dos operandos y el otro que realiza multiplicaciones de dos operandos.
De manera común a cada una de las pruebas voy a utilizar Apache Maven para manejar el ciclo de vida de cada componente que cree.
Spring Cloud y Spring Boot, dos facilitadores para el desarrollo.
Spring boot y Spring cloud son dos de las nuevas herramientas que Spring propone para facilitar el desarrollo de aplicaciones distribuidas basadas en microservicios.
Spring Boot es uno de los nuevos inventos de la familia Spring cuya pretensión es facilitar la vida a los desarrolladores simplificando todo el trabajo de configuración del propio framework. Para ello, Spring boot autoconfigura los componentes, automatizando la gestión de dependencias y el despliegue. Estas autoconfiguraciones son perfectas para los casos más comunes, pero en caso de necesitar algo más especial, las autoconfiguraciones pueden ser personalizadas utilizando anotaciones y/o ficheros de configuración.
Spring Cloud es otro de esos geniales inventos de la familia Spring que propone un ecosistema de herraminetas que nos ayudan a desplegar nuestros servicios en nubes. Soporta Cloud Foundry y Heroku de caja, así como otras nubes a través de conectores. Spring Cloud permitirá a las aplicaciones descubrir y compartir información/configuración de otras aplicaciones, y de sí misma, en tiempo de ejecución.
Servicios REST para la calculadora.
El primer paso para probar la tecnología de Spring es generar el servicio REST que va a proporcionar las operaciones aritméticas de suma y multiplicación de la calculadora.
Gracias a Spring Boot el desarrollo y pruebas de este API se hace muy rápidamente y con apenas esfuerzo.
El primer paso es crear un proyecto Java para contener el API REST. El proyecto se llama CalculadoraAritmeticaRestAPI.
Es importante fijarse que las únicas dependencias que he añadido han sido las referentes con spring boot. No he incluido ninguna dependencia referente al API REST. Ya se encargará Spring Boot de encontrar las dependencias necesarias para compilar y ejecutar correctamente el proyecto. Lo que si se ha añadido es el starter web para que Spring Boot tenga las dependencias necesarias para manejar aplicaciones web.
El siguiente paso es crear el servicio REST que proporciona las operaciones que se necesitan para la calculadora aritmética; sumar y multiplicar.
package com.tecnicomio.microservicios.spring;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/aritmetica")
public class CalculadoraAritmeticaRESTController {
public CalculadoraAritmeticaRESTController() {
}
@RequestMapping(
value = "/sumar",
method = RequestMethod.GET,
params = {"operando1", "operando2"}
)
public Integer sumar(@RequestParam("operando1") Integer operando1,
@RequestParam("operando2") Integer operando2) {
return operando1 + operando2;
}
@RequestMapping(
value = "/multiplicar",
method = RequestMethod.GET,
params = {"operando1", "operando2"}
)
public Integer multiplicar(@RequestParam("operando1") Integer operando1,
@RequestParam("operando2") Integer operando2) {
return operando1 * operando2;
}
}
No es el objetivo de esta entrada explicar cómo desarrollar servicios REST con Spring así que sólo comentaré que la principal anotación para convertir una clase Java en un API REST es @RestController. La otras anotaciones, leanse @RequestMapping y @RequestParam, sirven para configurar las funcionalidades que se exponen en el API. Ni que decir tiene que existen muchas más anotaciones y configuraciones, así que os dejo un link al tutorial de servicios REST de spring.io donde se explican bastante bien los conceptos:
Y finalmente, para que Spring Boot obre su magia se implementa una clase cuyo principal cometido es decirle a Spring que nos encontramos ante una aplicación web que contiene un servicio REST que debe publicarse para poder ser invocado.
package com.tecnicomio.microservicios.spring;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication(scanBasePackages = {"com.tecnicomio.microservicios.spring"})
public class CalculadoraAritmeticaServer {
public static void main(String[] args) {
SpringApplication.run(CalculadoraAritmeticaServer.class, args);
}
}
Podría haber incluido estas líneas directamente en el controller REST, pero he preferido por orden y limpieza crear esta mini clase como launcher.
Lo más curioso de Spring Boot es la inteligencia que incorpora, ya que al ejecutar estas 11 escasas líneas de código, Spring Boot sabe que se encuentra ante una aplicación web, con un servicio REST y arranca un Tomcat embebido para que se pueda acceder y ejecutar el servicio aritmético de calculadora.
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v1.5.10.RELEASE)
2018-03-15 12:37:48.853 INFO 121776 --- [ main] c.t.m.s.CalculadoraAritmeticaServer : Starting CalculadoraAritmeticaServer on devstation.localdomain with PID 121776 (/srv/java/src/pruebassimples/microservices/springfrwk/SumaAritmetica/target/classes started by developer in /srv/java/src/pruebassimples/microservices/springfrwk/SumaAritmetica)
2018-03-15 12:37:48.859 INFO 121776 --- [ main] c.t.m.s.CalculadoraAritmeticaServer : No active profile set, falling back to default profiles: default
2018-03-15 12:37:48.975 INFO 121776 --- [ main] ationConfigEmbeddedWebApplicationContext : Refreshing org.springframework.boot.context.embedded.AnnotationConfigEmbeddedWebApplicationContext@782859e: startup date [Thu Mar 15 12:37:48 CET 2018]; root of context hierarchy
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.springframework.cglib.core.ReflectUtils$1 (file:/home/developer/.m2/repository/org/springframework/spring-core/4.3.14.RELEASE/spring-core-4.3.14.RELEASE.jar) to method java.lang.ClassLoader.defineClass(java.lang.String,byte[],int,int,java.security.ProtectionDomain)
WARNING: Please consider reporting this to the maintainers of org.springframework.cglib.core.ReflectUtils$1
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
2018-03-15 12:37:50.549 INFO 121776 --- [ main] s.b.c.e.t.TomcatEmbeddedServletContainer : Tomcat initialized with port(s): 8080 (http)
2018-03-15 12:37:50.563 INFO 121776 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat]
2018-03-15 12:37:50.564 INFO 121776 --- [ main] org.apache.catalina.core.StandardEngine : Starting Servlet Engine: Apache Tomcat/8.5.27
2018-03-15 12:37:50.646 INFO 121776 --- [ost-startStop-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext
2018-03-15 12:37:50.646 INFO 121776 --- [ost-startStop-1] o.s.web.context.ContextLoader : Root WebApplicationContext: initialization completed in 1685 ms
2018-03-15 12:37:50.734 INFO 121776 --- [ost-startStop-1] o.s.b.w.servlet.ServletRegistrationBean : Mapping servlet: 'dispatcherServlet' to [/]
2018-03-15 12:37:50.737 INFO 121776 --- [ost-startStop-1] o.s.b.w.servlet.FilterRegistrationBean : Mapping filter: 'characterEncodingFilter' to: [/*]
2018-03-15 12:37:50.737 INFO 121776 --- [ost-startStop-1] o.s.b.w.servlet.FilterRegistrationBean : Mapping filter: 'hiddenHttpMethodFilter' to: [/*]
2018-03-15 12:37:50.737 INFO 121776 --- [ost-startStop-1] o.s.b.w.servlet.FilterRegistrationBean : Mapping filter: 'httpPutFormContentFilter' to: [/*]
2018-03-15 12:37:50.737 INFO 121776 --- [ost-startStop-1] o.s.b.w.servlet.FilterRegistrationBean : Mapping filter: 'requestContextFilter' to: [/*]
2018-03-15 12:37:51.154 INFO 121776 --- [ main] s.w.s.m.m.a.RequestMappingHandlerAdapter : Looking for @ControllerAdvice: org.springframework.boot.context.embedded.AnnotationConfigEmbeddedWebApplicationContext@782859e: startup date [Thu Mar 15 12:37:48 CET 2018]; root of context hierarchy
2018-03-15 12:37:51.218 INFO 121776 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/aritmetica/multiplicar],methods=[GET],params=[operando1 && operando2]}" onto public java.lang.Integer com.tecnicomio.microservicios.spring.CalculadoraAritmeticaRESTController.multiplicar(java.lang.Integer,java.lang.Integer)
2018-03-15 12:37:51.219 INFO 121776 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/aritmetica/sumar],methods=[GET],params=[operando1 && operando2]}" onto public java.lang.Integer com.tecnicomio.microservicios.spring.CalculadoraAritmeticaRESTController.sumar(java.lang.Integer,java.lang.Integer)
2018-03-15 12:37:51.221 INFO 121776 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/error]}" onto public org.springframework.http.ResponseEntity org.springframework.boot.autoconfigure.web.BasicErrorController.error(javax.servlet.http.HttpServletRequest)
2018-03-15 12:37:51.221 INFO 121776 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/error],produces=[text/html]}" onto public org.springframework.web.servlet.ModelAndView org.springframework.boot.autoconfigure.web.BasicErrorController.errorHtml(javax.servlet.http.HttpServletRequest,javax.servlet.http.HttpServletResponse)
2018-03-15 12:37:51.244 INFO 121776 --- [ main] o.s.w.s.handler.SimpleUrlHandlerMapping : Mapped URL path [/webjars/**] onto handler of type [class org.springframework.web.servlet.resource.ResourceHttpRequestHandler]
2018-03-15 12:37:51.244 INFO 121776 --- [ main] o.s.w.s.handler.SimpleUrlHandlerMapping : Mapped URL path [/**] onto handler of type [class org.springframework.web.servlet.resource.ResourceHttpRequestHandler]
2018-03-15 12:37:51.274 INFO 121776 --- [ main] o.s.w.s.handler.SimpleUrlHandlerMapping : Mapped URL path [/**/favicon.ico] onto handler of type [class org.springframework.web.servlet.resource.ResourceHttpRequestHandler]
2018-03-15 12:37:51.423 INFO 121776 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Registering beans for JMX exposure on startup
2018-03-15 12:37:51.537 INFO 121776 --- [ main] s.b.c.e.t.TomcatEmbeddedServletContainer : Tomcat started on port(s): 8080 (http)
2018-03-15 12:37:51.542 INFO 121776 --- [ main] c.t.m.s.CalculadoraAritmeticaServer : Started CalculadoraAritmeticaServer in 13.353 seconds (JVM running for 14.096)
Así que con un pom.xml y dos clases java muy simples tenemos el servicio REST publicado y accesible.
Documentando el API.
Para poder ejecutar los servicios expuestos debemos conocer la URL para invocarlo, los métodos que ofrece, los parámetros con que se llama a cada método y la información con la que se rellena.
Una manera de recibir esta información podría ser, por ejemplo, vía email, pero una mejor manera de recibirlo es tener un portal donde se pueda acceder a un listado de todos los servicios REST publicados y su información de uso. Este portal que concentra la información sobre APIs, es el objeto de la especificación Swagger.
La especificación swagger define un interfaz estándar para las APIs RESTful, que no se casa con ningún lenguaje de programación concreto, qué permite tanto a humanos como a máquinas descubrir y comprender las capacidades del servicio sin necesitad de acceder, ni al código fuente del mismo, ni a su documentación, ni a través de la inspección del comportamiento del servicio a través de la red. Cuando esta interfaz se define correctamente, los posibles consumidores del API pueden entender e interactuar correctamente con el servicio.
Springfox es la implementación de la especificación swagger que propone Spring. Para añadirla en nuestro servicio aritmético tenemos que seguir varios pasos.
El primero, añadir en el pom.xml la dependencia necesaria para utilizar Springfox.
El segundo es crear una clase de configuración de swagger.
package com.tecnicomio.microservicios.spring.com.tecnicomio.microservicios.spring.swagger;
import com.tecnicomio.microservicios.spring.CalculadoraAritmeticaRESTController;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import springfox.documentation.builders.ApiInfoBuilder;
import springfox.documentation.builders.PathSelectors;
import springfox.documentation.builders.RequestHandlerSelectors;
import springfox.documentation.service.ApiInfo;
import springfox.documentation.service.Contact;
import springfox.documentation.spi.DocumentationType;
import springfox.documentation.spring.web.plugins.Docket;
import springfox.documentation.swagger2.annotations.EnableSwagger2;
@Configuration
@EnableSwagger2
@ComponentScan(basePackageClasses = {CalculadoraAritmeticaRESTController.class})
public class SwaggerConfiguration {
@Bean
public Docket calculadoraAritmeticaApi() {
return new Docket(DocumentationType.SWAGGER_2)
.groupName("api-calculadora-aritmetica")
.apiInfo(apiInfo())
.select()
.apis(RequestHandlerSelectors.any())
.paths(PathSelectors.regex("/aritmetica.*"))
.build();
}
private ApiInfo apiInfo() {
return new ApiInfoBuilder()
.title("Calculadora aritmética API Rest")
.description("API RESTful para la calculadora aritmética.")
.termsOfServiceUrl("http://en.wikipedia.org/wiki/Terms_of_service")
.contact(new Contact("Eduardo González de Viñaspre", "http://tecnicomio.com", "eduardo.gonzalezdevinaspre@gmail.com"))
.license("Apache License Version 2.0")
.licenseUrl("http://www.apache.org/licenses/LICENSE-2.0.html")
.version("2.0")
.build();
}
}
Importante la anotación @EnableSwagger2 que indica que hay que activar swagger. El método calculadoraAritmeticaApi indica el formato de la documentación y su nombre, y el método apiInfo que indica información básica sobre la documentación que nos vamos a encontrar en el portal publicado.
Y finalmente documentar el controlador REST del API así como los POJOs que usemos para definir los parámetros de entrada y de salida de los diferentes métodos. En este caso como no hay POJOs, solo documento el controlador REST.
package com.tecnicomio.microservicios.spring;
import io.swagger.annotations.*;
import org.springframework.web.bind.annotation.*;
import javax.ws.rs.core.MediaType;
@RestController
@RequestMapping("/aritmetica")
@Api(value = "/aritmetica",
description = "Proporciona las operaciones necesarias para implementar una calculadora aritmética",
produces = "text/plain")
public class CalculadoraAritmeticaRESTController {
public CalculadoraAritmeticaRESTController() {
}
@RequestMapping(
value = "/sumar",
method = RequestMethod.GET,
params = {"operando1", "operando2"},
produces = MediaType.TEXT_PLAIN
)
@ApiOperation(value="Suma aritmética", notes = "Realiza la suma de dos operandos")
@ApiResponses( {
@ApiResponse(code = 200, message = "Devuelve el resultado de la suma.")
})
public Integer sumar(@RequestParam(value = "operando1",defaultValue = "0") @ApiParam(value = "operando 1 de la suma", defaultValue = "0", required = true, example = "5") Integer operando1,
@RequestParam(value = "operando2", defaultValue = "0") @ApiParam(value = "operando 2 de la suma", defaultValue = "0", required = true, example = "15") Integer operando2) {
return operando1 + operando2;
}
@RequestMapping(
value = "/multiplicar",
method = RequestMethod.GET,
params = {"operando1", "operando2"}
)
@ApiOperation(value="Multiplicación aritmética", notes = "Realiza la multiplicación de dos operandos")
@ApiResponses( {
@ApiResponse(code = 200, message = "Devuelve el resultado de la multiplicación.")
})
public Integer multiplicar(@RequestParam(value = "operando1", defaultValue = "1") @ApiParam(value = "operando 1 de la multiplicación", defaultValue = "1", required = true, example = "5") Integer operando1,
@RequestParam(value = "operando2", defaultValue = "1") @ApiParam(value = "operando 2 de la multiplicación", defaultValue = "1", required = true, example = "10") Integer operando2) {
return operando1 * operando2;
}
}
Las anotaciones que obran la magia son:
@Api – Define un contenedor de documentación.
@ApiOperation – Define la documentación de una operación dentro del servicio.
@ApiResponses y @ApiResponse – Documenta las respuestas del método del servicio.
@ApiParam- Documenta los parámetros de los parámetros de los métodos.
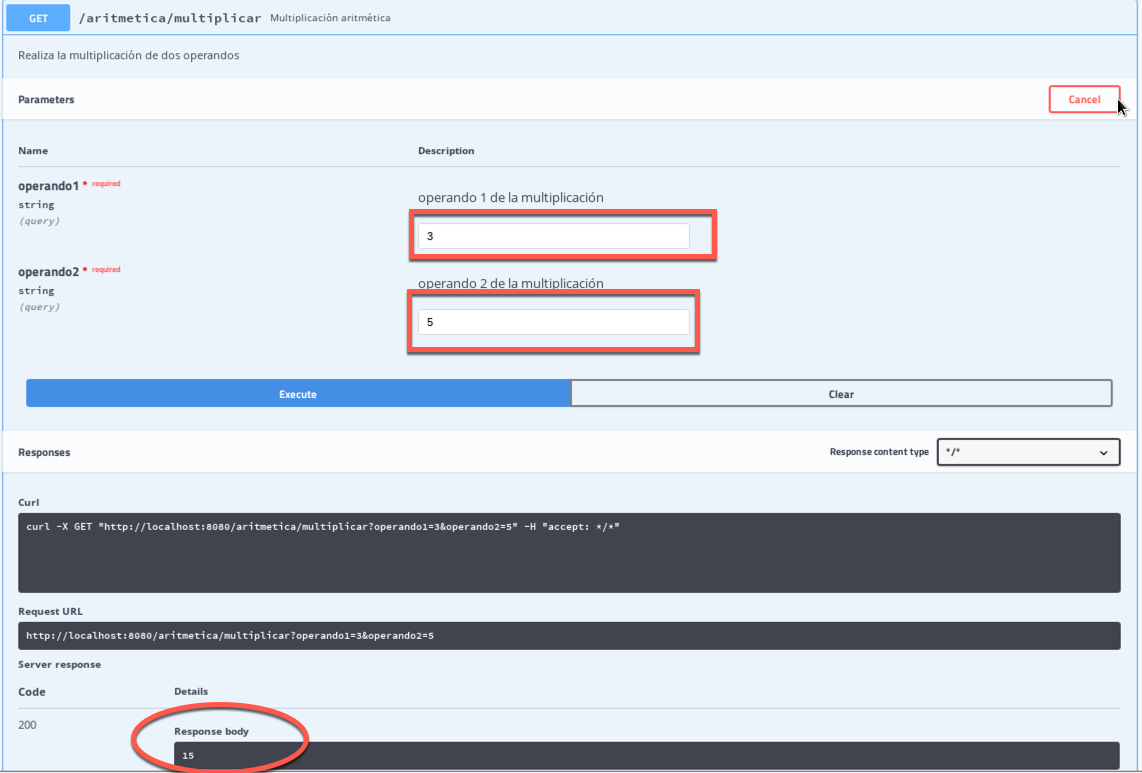
Gracias a Spring Boot no se necesita mucho más. Ahora ya se puede acceder a la URL de swagger: http://localhost:8080/swagger-ui.html# y si todo ha salido bien veremos la página que swagger ofrece con la documentación del servicio REST.
Si extendemos una operación, además de ver la documentación, podemos incluso llegar a probarla:
Arrancando una herramienta de Service Discovery: Eureka.
Al final la tecnología de microservicios está formada por servicios simples como el servicio de aritmética que acabamos de publicar, pero que además quedan envueltos por una ecosistema que aporta una serie de ventajas que facilitan el mantenimiento de estos servicios, por ejemplo, el registro y localización de los mismos, el balanceo de carga, la tolerancia a fallos, entre otros.
El registro de los servicios para su posterior localización y uso es importantísimo en cuanto tenemos un proyecto medio-grande entre manos. Basta con imaginar tener 100 microservicios dando servicio a un sitio web para darnos cuenta que tenemos que tener algún tipo de inventario con información sobre ellos. En el ecosistema de los microservicios la pieza que facilita este registro es el Service Discovery.
A día de hoy existen varios Service Discovery, algunos de los más importantes son:
Zookeeper de Apache Foundation
Eureka de Netflix
Consul
El siguiente paso por tanto es registrar el servicio aritmético en un Service Discovery, y para ello voy a utilizar Eureka, el Service Discovery que utiliza Netflix, una de las empresas que sirve más peticiones a lo largo y ancho de internet.
Lo primero que voy a hacer es crear un nuevo proyecto EurekaApplication para contener todo lo relativo a la ejecución de Eureka. El pom.xml del nuevo proyecto es:
¡¡Cuidado!! He tenido que añadir las dependencias de jaxb-api para que el Tomcat que Spring Boot incluye arranque correctamente. Esto es debido a que en la JDK 9 tras implementar los Java Modules, algunas librerías ya no se incluyen como si se hacía en la JDK 6/7/8. Uno de esos paquetes que no se incluye es java.xml.bind que contiene todo el funcionamiento de JAXB.
A continuación añado una clase para arrancar el servidor de Eureka.
package com.tecnicomio.microservicios.spring;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
@EnableEurekaServer
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
La anotación aquí es @EnableEurekaServer que le dice a Spring Boot que se quiere arrancar el Service Discovery de Eureka.
Y finalmente, para que configurar brevemente el servidor Eureka, se añade el fichero application.yml al directorio resources del proyecto.
En el fichero de configuración estamos indicando que el servidor de Eureka se arranque en el puerto 8761 (el puerto por defecto de los servidores de Eureka), que el cliente no se registre a si mismo ya que vamos a registrar el servicio aritmético.
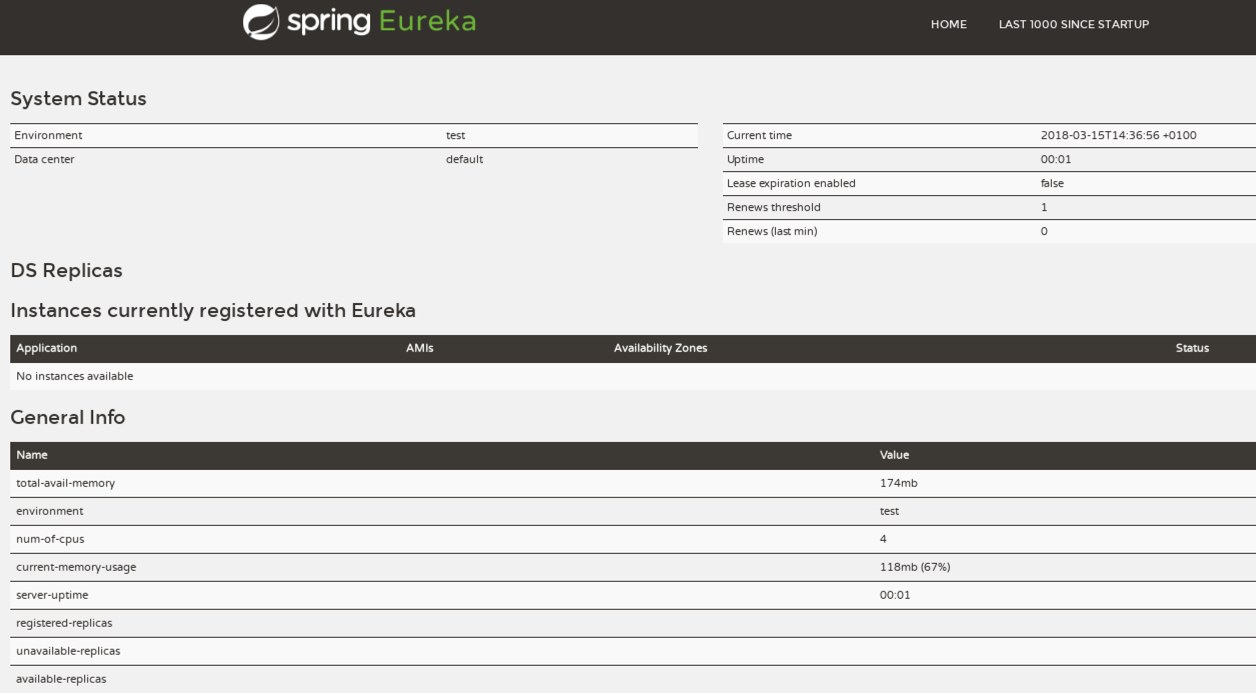
Así que finalmente, con estos pasos, ya deberíamos tener el servidor Eureka arrancado.
Con esto hemos conseguido que el servicio se autoregistre en Eureka, que le notifique cuando está disponible, cómo se le puede invocar, los metadatos que se pueden utilizar y mucha más información.
Descubriendo el servicio aritmético en Eureka.
Recapitulando, llegados a este punto hemos creado un servicio REST que ofrece funcionalidad para una calculadora aritmética, y hemos arrancado una instancia de Eureka, una herramienta para el descubrimiento de servicios.
Desafortunadamente, cuando miramos la consola de Eureka todavía no se ve registrado el servicio aritmético. Esto es debido a que hay que indicarle al servicio que implemente el Service Registry pattern de Eureka para convertirle en un posible cliente.
El primer paso es añadir las depedencias de Eureka al proyecto CalculadoraAritmeticaRestAPI:
El segundo indicarle al servicio aritmético que es un cliente de Eureka. Para ello añadimos la anotación @EnableEurekaClient a la clase servidor.
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
@EnableEurekaClient
@RestController
@RequestMapping("/aritmetica")
public class CalculadoraAritmeticaRESTController {
Y por último, configurar el cliente Eureka mediante un fichero application.yml donde indiquemos el nombre del micro-servicio, la URL y otras posibles configuraciones.
Hecho esto, se arranca el servicio CalculadoraAritmetica y automáticamente debería registrarse en el servidor Eureka indicado en el fichero YAML de configuración.
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v1.3.8.RELEASE)
2018-03-15 15:25:41.087 INFO 7659 --- [ main] c.t.m.s.CalculadoraAritmeticaServer : No active profile set, falling back to default profiles: default
2018-03-15 15:25:41.105 INFO 7659 --- [ main] ationConfigEmbeddedWebApplicationContext : Refreshing org.springframework.boot.context.embedded.AnnotationConfigEmbeddedWebApplicationContext@5942ee04: startup date [Thu Mar 15 15:25:41 CET 2018]; parent: org.springframework.context.annotation.AnnotationConfigApplicationContext@43b9fd5
2018-03-15 15:25:42.095 WARN 7659 --- [ main] o.s.c.a.ConfigurationClassPostProcessor : Cannot enhance @Configuration bean definition 'refreshScope' since its singleton instance has been created too early. The typical cause is a non-static @Bean method with a BeanDefinitionRegistryPostProcessor return type: Consider declaring such methods as 'static'.
2018-03-15 15:25:42.259 INFO 7659 --- [ main] o.s.cloud.context.scope.GenericScope : BeanFactory id=357c0c59-b5b5-38af-babc-0373b7d67e30
2018-03-15 15:25:42.275 INFO 7659 --- [ main] f.a.AutowiredAnnotationBeanPostProcessor : JSR-330 'javax.inject.Inject' annotation found and supported for autowiring
2018-03-15 15:25:42.328 INFO 7659 --- [ main] trationDelegate$BeanPostProcessorChecker : Bean 'org.springframework.cloud.autoconfigure.ConfigurationPropertiesRebinderAutoConfiguration' of type [class org.springframework.cloud.autoconfigure.ConfigurationPropertiesRebinderAutoConfiguration$$EnhancerBySpringCGLIB$$defd02e1] is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying)
2018-03-15 15:25:42.335 INFO 7659 --- [ main] trationDelegate$BeanPostProcessorChecker : Bean 'org.springframework.cloud.autoconfigure.RefreshEndpointAutoConfiguration' of type [class org.springframework.cloud.autoconfigure.RefreshEndpointAutoConfiguration$$EnhancerBySpringCGLIB$$885c04d7] is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying)
2018-03-15 15:25:42.710 INFO 7659 --- [ main] s.b.c.e.t.TomcatEmbeddedServletContainer : Tomcat initialized with port(s): 0 (http)
2018-03-15 15:25:42.728 INFO 7659 --- [ main] o.apache.catalina.core.StandardService : Starting service Tomcat
2018-03-15 15:25:42.729 INFO 7659 --- [ main] org.apache.catalina.core.StandardEngine : Starting Servlet Engine: Apache Tomcat/8.0.37
2018-03-15 15:25:42.850 INFO 7659 --- [ost-startStop-1] org.apache.catalina.loader.WebappLoader : Unknown loader jdk.internal.loader.ClassLoaders$AppClassLoader@1b9e1916 class jdk.internal.loader.ClassLoaders$AppClassLoader
2018-03-15 15:25:42.868 INFO 7659 --- [ost-startStop-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext
2018-03-15 15:25:42.868 INFO 7659 --- [ost-startStop-1] o.s.web.context.ContextLoader : Root WebApplicationContext: initialization completed in 1764 ms
2018-03-15 15:25:43.278 INFO 7659 --- [ost-startStop-1] o.s.b.c.e.ServletRegistrationBean : Mapping servlet: 'dispatcherServlet' to [/]
2018-03-15 15:25:43.282 INFO 7659 --- [ost-startStop-1] o.s.b.c.embedded.FilterRegistrationBean : Mapping filter: 'metricsFilter' to: [/*]
2018-03-15 15:25:43.282 INFO 7659 --- [ost-startStop-1] o.s.b.c.embedded.FilterRegistrationBean : Mapping filter: 'characterEncodingFilter' to: [/*]
2018-03-15 15:25:43.282 INFO 7659 --- [ost-startStop-1] o.s.b.c.embedded.FilterRegistrationBean : Mapping filter: 'hiddenHttpMethodFilter' to: [/*]
2018-03-15 15:25:43.282 INFO 7659 --- [ost-startStop-1] o.s.b.c.embedded.FilterRegistrationBean : Mapping filter: 'httpPutFormContentFilter' to: [/*]
2018-03-15 15:25:43.283 INFO 7659 --- [ost-startStop-1] o.s.b.c.embedded.FilterRegistrationBean : Mapping filter: 'requestContextFilter' to: [/*]
2018-03-15 15:25:43.283 INFO 7659 --- [ost-startStop-1] o.s.b.c.embedded.FilterRegistrationBean : Mapping filter: 'webRequestLoggingFilter' to: [/*]
2018-03-15 15:25:43.283 INFO 7659 --- [ost-startStop-1] o.s.b.c.embedded.FilterRegistrationBean : Mapping filter: 'applicationContextIdFilter' to: [/*]
2018-03-15 15:25:44.388 INFO 7659 --- [ main] o.s.cloud.commons.util.InetUtils : Cannot determine local hostname
2018-03-15 15:25:44.737 INFO 7659 --- [ main] s.w.s.m.m.a.RequestMappingHandlerAdapter : Looking for @ControllerAdvice: org.springframework.boot.context.embedded.AnnotationConfigEmbeddedWebApplicationContext@5942ee04: startup date [Thu Mar 15 15:25:41 CET 2018]; parent: org.springframework.context.annotation.AnnotationConfigApplicationContext@43b9fd5
2018-03-15 15:25:44.866 INFO 7659 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/aritmetica/sumar],methods=[GET],params=[operando1 && operando2]}" onto public java.lang.Integer com.tecnicomio.microservicios.spring.CalculadoraAritmeticaRESTController.sumar(java.lang.Integer,java.lang.Integer)
2018-03-15 15:25:44.867 INFO 7659 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/aritmetica/multiplicar],methods=[GET],params=[operando1 && operando2]}" onto public java.lang.Integer com.tecnicomio.microservicios.spring.CalculadoraAritmeticaRESTController.multiplicar(java.lang.Integer,java.lang.Integer)
2018-03-15 15:25:44.869 INFO 7659 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/error]}" onto public org.springframework.http.ResponseEntity org.springframework.boot.autoconfigure.web.BasicErrorController.error(javax.servlet.http.HttpServletRequest)
2018-03-15 15:25:44.869 INFO 7659 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/error],produces=[text/html]}" onto public org.springframework.web.servlet.ModelAndView org.springframework.boot.autoconfigure.web.BasicErrorController.errorHtml(javax.servlet.http.HttpServletRequest,javax.servlet.http.HttpServletResponse)
2018-03-15 15:25:44.897 INFO 7659 --- [ main] o.s.w.s.handler.SimpleUrlHandlerMapping : Mapped URL path [/webjars/**] onto handler of type [class org.springframework.web.servlet.resource.ResourceHttpRequestHandler]
2018-03-15 15:25:44.897 INFO 7659 --- [ main] o.s.w.s.handler.SimpleUrlHandlerMapping : Mapped URL path [/**] onto handler of type [class org.springframework.web.servlet.resource.ResourceHttpRequestHandler]
2018-03-15 15:25:44.941 INFO 7659 --- [ main] o.s.w.s.handler.SimpleUrlHandlerMapping : Mapped URL path [/**/favicon.ico] onto handler of type [class org.springframework.web.servlet.resource.ResourceHttpRequestHandler]
2018-03-15 15:25:45.415 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/pause || /pause.json],methods=[POST]}" onto public java.lang.Object org.springframework.cloud.endpoint.GenericPostableMvcEndpoint.invoke()
2018-03-15 15:25:45.416 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/beans || /beans.json],methods=[GET],produces=[application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.mvc.EndpointMvcAdapter.invoke()
2018-03-15 15:25:45.417 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/env],methods=[POST]}" onto public java.lang.Object org.springframework.cloud.context.environment.EnvironmentManagerMvcEndpoint.value(java.util.Map)
2018-03-15 15:25:45.417 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/env/reset],methods=[POST]}" onto public java.util.Map org.springframework.cloud.context.environment.EnvironmentManagerMvcEndpoint.reset()
2018-03-15 15:25:45.420 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/trace || /trace.json],methods=[GET],produces=[application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.mvc.EndpointMvcAdapter.invoke()
2018-03-15 15:25:45.421 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/dump || /dump.json],methods=[GET],produces=[application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.mvc.EndpointMvcAdapter.invoke()
2018-03-15 15:25:45.422 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/mappings || /mappings.json],methods=[GET],produces=[application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.mvc.EndpointMvcAdapter.invoke()
2018-03-15 15:25:45.423 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/restart || /restart.json],methods=[POST]}" onto public java.lang.Object org.springframework.cloud.context.restart.RestartMvcEndpoint.invoke()
2018-03-15 15:25:45.424 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/features || /features.json],methods=[GET],produces=[application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.mvc.EndpointMvcAdapter.invoke()
2018-03-15 15:25:45.424 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/env/{name:.*}],methods=[GET],produces=[application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.mvc.EnvironmentMvcEndpoint.value(java.lang.String)
2018-03-15 15:25:45.425 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/env || /env.json],methods=[GET],produces=[application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.mvc.EndpointMvcAdapter.invoke()
2018-03-15 15:25:45.425 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/configprops || /configprops.json],methods=[GET],produces=[application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.mvc.EndpointMvcAdapter.invoke()
2018-03-15 15:25:45.426 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/archaius || /archaius.json],methods=[GET],produces=[application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.mvc.EndpointMvcAdapter.invoke()
2018-03-15 15:25:45.427 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/health || /health.json],produces=[application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.mvc.HealthMvcEndpoint.invoke(java.security.Principal)
2018-03-15 15:25:45.427 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/info || /info.json],methods=[GET],produces=[application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.mvc.EndpointMvcAdapter.invoke()
2018-03-15 15:25:45.428 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/refresh || /refresh.json],methods=[POST]}" onto public java.lang.Object org.springframework.cloud.endpoint.GenericPostableMvcEndpoint.invoke()
2018-03-15 15:25:45.429 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/metrics/{name:.*}],methods=[GET],produces=[application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.mvc.MetricsMvcEndpoint.value(java.lang.String)
2018-03-15 15:25:45.429 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/metrics || /metrics.json],methods=[GET],produces=[application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.mvc.EndpointMvcAdapter.invoke()
2018-03-15 15:25:45.430 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/resume || /resume.json],methods=[POST]}" onto public java.lang.Object org.springframework.cloud.endpoint.GenericPostableMvcEndpoint.invoke()
2018-03-15 15:25:45.431 INFO 7659 --- [ main] o.s.b.a.e.mvc.EndpointHandlerMapping : Mapped "{[/autoconfig || /autoconfig.json],methods=[GET],produces=[application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.mvc.EndpointMvcAdapter.invoke()
2018-03-15 15:25:45.554 INFO 7659 --- [ main] o.s.ui.freemarker.SpringTemplateLoader : SpringTemplateLoader for FreeMarker: using resource loader [org.springframework.boot.context.embedded.AnnotationConfigEmbeddedWebApplicationContext@5942ee04: startup date [Thu Mar 15 15:25:41 CET 2018]; parent: org.springframework.context.annotation.AnnotationConfigApplicationContext@43b9fd5] and template loader path [classpath:/templates/]
2018-03-15 15:25:45.555 INFO 7659 --- [ main] o.s.w.s.v.f.FreeMarkerConfigurer : ClassTemplateLoader for Spring macros added to FreeMarker configuration
2018-03-15 15:25:45.634 WARN 7659 --- [ main] c.n.c.sources.URLConfigurationSource : No URLs will be polled as dynamic configuration sources.
2018-03-15 15:25:45.634 INFO 7659 --- [ main] c.n.c.sources.URLConfigurationSource : To enable URLs as dynamic configuration sources, define System property archaius.configurationSource.additionalUrls or make config.properties available on classpath.
2018-03-15 15:25:45.642 WARN 7659 --- [ main] c.n.c.sources.URLConfigurationSource : No URLs will be polled as dynamic configuration sources.
2018-03-15 15:25:45.642 INFO 7659 --- [ main] c.n.c.sources.URLConfigurationSource : To enable URLs as dynamic configuration sources, define System property archaius.configurationSource.additionalUrls or make config.properties available on classpath.
2018-03-15 15:25:45.689 WARN 7659 --- [ main] arterDeprecationWarningAutoConfiguration : spring-cloud-starter-eureka-server is deprecated as of Spring Cloud Netflix 1.4.0, please migrate to spring-cloud-starter-netflix-eureka-server
2018-03-15 15:25:45.768 INFO 7659 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Registering beans for JMX exposure on startup
2018-03-15 15:25:45.784 INFO 7659 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Bean with name 'refreshScope' has been autodetected for JMX exposure
2018-03-15 15:25:45.784 INFO 7659 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Bean with name 'environmentManager' has been autodetected for JMX exposure
2018-03-15 15:25:45.786 INFO 7659 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Bean with name 'configurationPropertiesRebinder' has been autodetected for JMX exposure
2018-03-15 15:25:45.787 INFO 7659 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Bean with name 'refreshEndpoint' has been autodetected for JMX exposure
2018-03-15 15:25:45.788 INFO 7659 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Bean with name 'restartEndpoint' has been autodetected for JMX exposure
2018-03-15 15:25:45.794 INFO 7659 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Located managed bean 'environmentManager': registering with JMX server as MBean [org.springframework.cloud.context.environment:name=environmentManager,type=EnvironmentManager]
2018-03-15 15:25:45.816 INFO 7659 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Located managed bean 'restartEndpoint': registering with JMX server as MBean [org.springframework.cloud.context.restart:name=restartEndpoint,type=RestartEndpoint]
2018-03-15 15:25:45.827 INFO 7659 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Located managed bean 'refreshScope': registering with JMX server as MBean [org.springframework.cloud.context.scope.refresh:name=refreshScope,type=RefreshScope]
2018-03-15 15:25:45.832 INFO 7659 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Located managed bean 'configurationPropertiesRebinder': registering with JMX server as MBean [org.springframework.cloud.context.properties:name=configurationPropertiesRebinder,context=5942ee04,type=ConfigurationPropertiesRebinder]
2018-03-15 15:25:45.848 INFO 7659 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Located managed bean 'refreshEndpoint': registering with JMX server as MBean [org.springframework.cloud.endpoint:name=refreshEndpoint,type=RefreshEndpoint]
2018-03-15 15:25:46.013 INFO 7659 --- [ main] o.s.c.support.DefaultLifecycleProcessor : Starting beans in phase 0
2018-03-15 15:25:46.158 INFO 7659 --- [ main] s.b.c.e.t.TomcatEmbeddedServletContainer : Tomcat started on port(s): 42809 (http)
2018-03-15 15:25:46.158 INFO 7659 --- [ main] c.n.e.EurekaDiscoveryClientConfiguration : Updating port to 42809
2018-03-15 15:25:46.168 INFO 7659 --- [ main] o.s.c.n.eureka.InstanceInfoFactory : Setting initial instance status as: STARTING
2018-03-15 15:25:46.741 INFO 7659 --- [ main] c.n.d.provider.DiscoveryJerseyProvider : Using JSON encoding codec LegacyJacksonJson
2018-03-15 15:25:46.743 INFO 7659 --- [ main] c.n.d.provider.DiscoveryJerseyProvider : Using JSON decoding codec LegacyJacksonJson
2018-03-15 15:25:46.877 INFO 7659 --- [ main] c.n.d.provider.DiscoveryJerseyProvider : Using XML encoding codec XStreamXml
2018-03-15 15:25:46.878 INFO 7659 --- [ main] c.n.d.provider.DiscoveryJerseyProvider : Using XML decoding codec XStreamXml
2018-03-15 15:25:47.112 INFO 7659 --- [ main] c.n.d.s.r.aws.ConfigClusterResolver : Resolving eureka endpoints via configuration
2018-03-15 15:25:47.140 INFO 7659 --- [ main] com.netflix.discovery.DiscoveryClient : Disable delta property : false
2018-03-15 15:25:47.140 INFO 7659 --- [ main] com.netflix.discovery.DiscoveryClient : Single vip registry refresh property : null
2018-03-15 15:25:47.140 INFO 7659 --- [ main] com.netflix.discovery.DiscoveryClient : Force full registry fetch : false
2018-03-15 15:25:47.140 INFO 7659 --- [ main] com.netflix.discovery.DiscoveryClient : Application is null : false
2018-03-15 15:25:47.140 INFO 7659 --- [ main] com.netflix.discovery.DiscoveryClient : Registered Applications size is zero : true
2018-03-15 15:25:47.140 INFO 7659 --- [ main] com.netflix.discovery.DiscoveryClient : Application version is -1: true
2018-03-15 15:25:47.140 INFO 7659 --- [ main] com.netflix.discovery.DiscoveryClient : Getting all instance registry info from the eureka server
2018-03-15 15:25:47.657 INFO 7659 --- [ main] com.netflix.discovery.DiscoveryClient : The response status is 200
2018-03-15 15:25:47.658 INFO 7659 --- [ main] com.netflix.discovery.DiscoveryClient : Starting heartbeat executor: renew interval is: 30
2018-03-15 15:25:47.667 INFO 7659 --- [ main] c.n.discovery.InstanceInfoReplicator : InstanceInfoReplicator onDemand update allowed rate per min is 4
2018-03-15 15:25:47.670 INFO 7659 --- [ main] com.netflix.discovery.DiscoveryClient : Discovery Client initialized at timestamp 1521123947669 with initial instances count: 0
2018-03-15 15:25:47.696 INFO 7659 --- [ main] c.n.e.EurekaDiscoveryClientConfiguration : Registering application calculadora-aritmetica-eureka-client with eureka with status UP
2018-03-15 15:25:47.697 INFO 7659 --- [ main] com.netflix.discovery.DiscoveryClient : Saw local status change event StatusChangeEvent [timestamp=1521123947697, current=UP, previous=STARTING]
2018-03-15 15:25:47.715 INFO 7659 --- [ main] c.t.m.s.CalculadoraAritmeticaServer : Started CalculadoraAritmeticaServer in 11.699 seconds (JVM running for 12.527)
2018-03-15 15:25:47.716 INFO 7659 --- [nfoReplicator-0] com.netflix.discovery.DiscoveryClient : DiscoveryClient_CALCULADORA-ARITMETICA-EUREKA-CLIENT/localhost:calculadora-aritmetica-eureka-client:0: registering service...
2018-03-15 15:25:47.867 INFO 7659 --- [nfoReplicator-0] com.netflix.discovery.DiscoveryClient : DiscoveryClient_CALCULADORA-ARITMETICA-EUREKA-CLIENT/localhost:calculadora-aritmetica-eureka-client:0 - registration status: 204
2018-03-15 15:26:14.100 INFO 7659 --- [o-auto-1-exec-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring FrameworkServlet 'dispatcherServlet'
2018-03-15 15:26:14.100 INFO 7659 --- [o-auto-1-exec-1] o.s.web.servlet.DispatcherServlet : FrameworkServlet 'dispatcherServlet': initialization started
2018-03-15 15:26:14.129 INFO 7659 --- [o-auto-1-exec-1] o.s.web.servlet.DispatcherServlet : FrameworkServlet 'dispatcherServlet': initialization completed in 29 ms
2018-03-15 15:26:17.659 INFO 7659 --- [freshExecutor-0] com.netflix.discovery.DiscoveryClient : Disable delta property : false
2018-03-15 15:26:17.659 INFO 7659 --- [freshExecutor-0] com.netflix.discovery.DiscoveryClient : Single vip registry refresh property : null
2018-03-15 15:26:17.659 INFO 7659 --- [freshExecutor-0] com.netflix.discovery.DiscoveryClient : Force full registry fetch : false
2018-03-15 15:26:17.659 INFO 7659 --- [freshExecutor-0] com.netflix.discovery.DiscoveryClient : Application is null : false
2018-03-15 15:26:17.659 INFO 7659 --- [freshExecutor-0] com.netflix.discovery.DiscoveryClient : Registered Applications size is zero : true
2018-03-15 15:26:17.659 INFO 7659 --- [freshExecutor-0] com.netflix.discovery.DiscoveryClient : Application version is -1: false
2018-03-15 15:26:17.659 INFO 7659 --- [freshExecutor-0] com.netflix.discovery.DiscoveryClient : Getting all instance registry info from the eureka server
2018-03-15 15:26:17.709 INFO 7659 --- [freshExecutor-0] com.netflix.discovery.DiscoveryClient : The response status is 200
Estableciendo un Gateway API para dar acceso a los servicios
Llegados a este punto tenemos:
Un servicio REST para operaciones aritméticas
El servicios REST de operaciones aritméticas documentado con Swagger, y está documentación accesible a través de una URL
Eureka, el Registry Discovery de NETFLIX arrancado
El servicio REST de operaciones aritméticas capaz de ser detectado por el Registry Discovery.
La ultima pieza que voy a incluir en este ecosistema de microservicios es el Gateway que concentra las llamadas de los clientes. La verdad es que el ejemplo que estoy utilizando se queda un poco corto para entender porque es necesario un gateway, total, solo tenemos un servicio publicado en una máquina al que podemos acceder desde una única URL.
Pero, ¿qué pasaría si tuviera 10 servicios cada uno con su URL propia? Tendría 10 urls, cada una diferente y cada una con su documentación swagger. El API Gateway viene al rescate y ofrece un único punto de acceso, una URL de invocación homogénea y una única documentación swagger.
El API Gateway en el que voy a integrar mi API de operaciones aritméticas va a ser ZUUL, el API Gateway de Netflix.
Las expresiones lambda no son complejas de usar y entre otras ventajas permiten pasar comportamiento como valor, algo muy utilizado en Javascript, y abreviar líneas de código sin perder legibilidad en el código. Es por esto que Java las adoptó definitivamente en la JavaSE 8. Pero, para que las expresiones lambda sean verdaderamente útiles, hay que llegar a entenderlas. Hasta que eso ocurre pueden llegar a ser bastante confusas.
Si nos atenemos a la definición oficial de expresión lambda diríamos que son funciones anónimas que implementan una interfaz funcional, que así dicho suena muy técnico, pero si te lo dicen así sin más, puede dejarte algo frío. A mi es lo que me pasó, así que me puse manos a la obra para intentar aterrizar el concepto y desgranar la definición teórica haciéndola comprensible para mortales como yo. De ese germen surgió esta entrada.
Lo que me quedó claro de la definición es qué, para entender las expresiones lambda hay que entender qué es una función anónima y que es una interfaz funcional.
Función anónima
Las funciones anónimas permiten crear instancias de un objeto que implementa un interfaz en particular sin que para ello sea necesario desarrollar la clase que implementa esa interfaz explícitamente.
¡Toma ya!
Esto se ve claro con un ejemplo. Imaginemos una interfaz que ofrece métodos para una calculadora:
Repasando qué hemos conseguido con la función anónima, llegamos a las siguientes conclusiones:
Nos hemos ahorrado la definición y creación de la clase, que en el caso de clases que se usan en un único sitio, puede ser un gran ahorro. Así evitamos contaminar el proyecto con esas clases que no se reutilizan en otras partes.
Cuando la implementación es corta, como en el caso de este ejemplo, en el que el código se encuentre directamente en el lugar donde se usa, puede hacer que éste sea más entendible (aunque tal vez menos legible).
Permite seguir manejando correctamente las variables locales y miembros de la clase sin tener que definir un constructor para poder recibirlas y usarlas.
En este ejemplo, es probable que el ahorro de crear la clase, versus la disminución de legibilidad, haga que no merezca suficientemente la pena, pero pongamos un ejemplo donde verdaderamente las funciones anónimas dan la talla. Imaginemos una ventana con 15 botones y sus respectivos 15 event listeners cada vez que el usuario hace click en ellos. En este caso, habría que crear 15 clases donde cada una implementa el interfaz ActionListener. Clases que solo se usan en el punto del código donde se implementa el formulario. En este caso, usar funciones anónimas es mucho más rentable.
Interfaz Funcional
Un interfaz funcional es aquel interfaz que tiene únicamente un método y este método es abstracto, es decir un método sin implementar. Las interfaces funcionales fueron agregadas a partir de la versión JavaSE 8 y vienen de la mano de las expresiones lambda.
A continuación dos ejemplos de interfaz funcional. El primero es un ejemplo al uso, con un único método abstracto.
package com.tecnicomio.interfazfuncional;
public interface IInterfazFuncionalSimple {
public String saludo(String nombre);
}
El segundo es un ejemplo un poco más rebuscado pero igualmente válido; un único método abstracto y varios métodos default.
package com.tecnicomio.interfazfuncional;
public interface IInterfazFuncionalRebuscada {
public String saludo(String nombre);
public default String holaMundo() {
Return "Hola mundo.";
}
}
Para asegurarnos que la interfaz cumple con las reglas de las interfaces funcionales podríamos anotar la interfaz con @FunctionalInterface. En este caso si introdujéramos más de un método abstracto (sin implementación) el compilador nos daría el error: «Multiple non overriding abstract methods found in interface com.tecnicomio.pruebas.interfazfuncional.InterfazFuncionalAnotada». En caso de no introducir ningún método abstracto, nos daría el error: «No Target method found».
package com.tecnicomio.interfazfuncional;
@FunctionalInterface
public interface IInterfazFuncionalAnotada {
public String saludo(String nombre);
public default String holaMundo() {
Return "Hola mundo.";
}
}
En el ejemplo de la calculadora, la interfaz ICalculadora es un claro ejemplo de Interfaz Funcional, sin anotar.
Expresiones lambda
Y ahora que ya han quedado un poco más claros los conceptos «funciones anónimas» e «interfaces funcionales» volvamos a la definición de expresión lambda: las expresiones lambda son funciones anónimas que implementan una interfaz funcional.
Por tanto, podríamos decir que son una evolución de las funciones anónimas que pretenden simplificar aún más el código, pero que para conseguir esta simplificación, obligan a que la funcionalidad de la expresión lambda implemente una interfaz funcional.
Sintaxis de las expresiones lambda
La sintaxis de las expresiones lambda es:
(Parametros) -> { cuerpo expresión lambda }
Teniendo en cuenta qué:
El operador lambda (->) separa la declaración de parámetros del cuerpo de la función.
Parámetros
Cuando se tiene un solo parámetro pueden omitirse los paréntesis.
Cuando no se tienen parámetros, o cuando se tienen dos o más, sí es necesario su uso.
Cuerpo de la expresión lambda
Cuando el cuerpo de la expresión lambda tiene una única línea pueden omitirse las llaves y no se necesita especificar la cláusula return en el caso de que se devuelva valor.
Ejemplos de expresiones lambda pueden ser:
Expresión lambda con un único parámetro y una única línea: num -> num+10
Expresión lambda sin parámetros y una única línea: () -> System.out.println(«Hola mundo»)
Expresión lambda con dos parámetros y una única línea: (int operando1, int operando2) -> operando1 * operando2
Expresión lambda con múltiples parámetros y varias líneas de función: (String nombre) -> {String retorno=»Hola «; retorno=retorno.concat(nombre); return retorno;}
La calculadora con expresiones lambda
Y como lo mejor para entender algo es verlo con un ejemplo, apliquemos las expresiones lambda al ejemplo de la calculadora que podría quedar así:
O si queremos ahorrar aún más líneas de código sin perder legibilidad podría quedar de esta otra forma:
System.out.println("En una línea:10+22=" + ((ICalculadora)(Integer operando1, Integer operando2)->(operando1+operando2)).suma(10,22));
Conclusiones
Como se puede ver en el ejemplo de la calculadora utilizar expresiones lambda tienen claros y algunos obscuros.
Para mí los claros son:
Al hacer uso de funciones anónimas sin necesidad de crear clases anónimas se crea código más claro y conciso.
Acercan Java a la programación funcional muy utilizado en lenguajes de script, como Javascript, donde las funciones juegan un papel protagonista. Esto permite poder pasar funciones como valores de variables, valores de retorno o parámetros de otras funciones, es decir, gracias a las expresiones lambda se puede pasar comportamiento como valor.
Al usarlas en combinación con la API Stream se pueden realizar operaciones de tipo filtro/mapeo sobre colecciones de datos de forma secuencial o paralela siendo la implementación transparente al desarrollador.
Logran un código más compacto y fácil de leer.
Reducen la escritura de código.
El oscuro para mí es claro:
Hay que entenderlas para sacarles el máximo partido. Y entenderlas es cambiar la manera de pensar del javero de toda la vida.
Al hilo de un problema de seguridad informática que vivimos el año pasado mientras trabajaba desplazado en un cliente. La crisis que se produjo, hizo patente la necesidad de un sistema de comunicaciones corporativo y ágil para transmitir mensajes de interés general a los empleados de la compañía en momentos determinados.
Un poco de información de contexto.
Entre otros muchos canales, SMS, EMAIL, llamadas de teléfono, el CTO de la compañía propuso utilizar WhatsApp como herramienta que podría cubrir las necesidades de comunicación al personal de la empresa. La idea a priori sonaba viable y le dimos prioridad. WhatsApp es una aplicación con una gran difusión, casi todo el mundo la tiene instalada en sus móvil. Dispone de un interfaz web para facilitar su uso desde ordenadores y no solo desde elementos de movilidad. Su principal cometido es poner en contacto a personas. La estabilidad de WhatsApp parece más que probada en sus casi 10 años de servicio. Parecía un candidato adecuado y fuerte.
Desgraciadamente, en el momento del estudio nos topamos con varias pegas. La principal fue que la licencia de WhatsApp es una licencia de uso personal, WhatsApp no está diseñado para ser usado por un ente, empresa o similar. Es por este motivo que WhatsApp no permite el uso de su plataforma para el envío masivo de mensajes.
Uso legal y aceptable. Debes acceder a nuestros Servicios y usarlos solo con fines legales, autorizados y aceptables. No usarás (o ayudarás a que otros usen) nuestros Servicios en formas que: (a) (…) (e) impliquen el envío de comunicaciones ilegales o inadmisibles, como mensajería masiva, mensajería automática, marcado automático y metodologías similares; o (f) impliquen cualquier otro uso no personal de nuestros Servicios a menos que nosotros autoricemos lo contrario.
Como todavía no queríamos rendirnos prematuramente y desechar WhatsApp como herramienta, pensamos en sortear estos impedimentos legales creando un perfil personal corporativo que actuará como fuente de información y posteriormente crear un grupo donde incluir a los empleados. La empresa para la que trabajamos supera los 3000 empleados, y aquí es donde encontramos un nuevo handicap, whatsapp solo permite grupos de 256 sujetos.
Sin tirar la toalla todavía, encontramos la posibilidad de utilizar servicios de terceros que a través de whatsapp ofrecen el envío masivo de mensajes. Dos eran las empresas que destacaban ofreciendo estos servicios: MassyPhone y WhatsAppMarketing.
Después de investigar esta vía, tuvimos que descartarla por los siguientes motivos:
El primero es que teníamos que entregar a éstas empresas los números de teléfono de los empleados, lo que iba en contra de la política de privacidad.
El Segundo fue que tras investigar el funcionamiento de estos servicios descubrimos qué, como legalmente Whatsapp no permite el envío masivo de mensajes, estas empresas usan un pool de teléfonos para permitir el envío masivo sin ser inhabilitados. No nos pareció una buena práctica apostar por empresas que usan el servicio de una manera que el propio WhatsApp prohibe.
Además, los mensajes serían enviados desde diferentes números de teléfonos cambiantes, lo que impediría al empleado corroborar la veracidad de la fuente y abría una puerta al envío de mensajes falsos y maliciosos.
Llegados a este punto, decidimos abandonar la idea de utilizar Whatsapp para el envío de información y seguir confiando en el envío masivo de SMS, pues la alternativa no era viable.
Whatsapp para empresas
Finalmente, hoy anuncia WhatsApp que ha creado una aplicación llamada WhatsApp para empresas (o Whatsapp Business en inglés) que permite a las pequeñas y medianas empresas interactuar con personas pudiendo utilizar herramientas de automatización, organización y respuesta rápida a mensajes.
La aplicación permite crear un perfil de empresa con información interesante sobre el negocio desempeñado, horario, ubicación, etcétera. Permite establecer mensajes de ausencia donde se indique el horario para poder contactar, mensajes de bienvenida, respuestas rápidas que permite guardar en la aplicación mensajes que se envían de manera frecuente y así reutilizarlos para responder a las preguntas más rápidamente.
De momento la aplicación está sólo disponible para Android, aunque se espera una versión iOS no muy lejos en el tiempo, y solo está disponible para Indonesia, Italia, México, Reino Unido y Estados Unidos, pero se espera su expansión en pocas semanas en el resto del mundo.
Conclusión
Aunque esta nueva aplicación empresarial de Whatsapp tampoco soluciona nuestra premisa de comunicación masiva a los empleados, va avanzando en el camino adecuado para que en un futuro no muy lejano Whatsapp se convierta en la solución empresarial para la interacción empresa-empleado y empresa-cliente. Habrá que seguir con interés lo qué nos depara el futuro.
Estoy participando en un proyecto para realizar el seguimiento de tareas internas en una compañía de distribución comercial de bienes y servicios. Para llevar a cabo correctamente esta gestión de tareas decidimos instalar la solución JIRA de la compañía Atlassian. Sobre esta herramienta instalamos un par de plugins a través del marketplace y realizamos la configuración de tres workflows para el seguimiento personalizado de las tareas. Como este sistema de seguimiento no era crítico para la compañía decidimos crear dos instalaciones diferenciadas: la instalación de desarrollo, donde desarrollar y probar las configuraciones y nuevos desarrollos, y una instalación productiva donde la compañía llevaría a cabo su trabajo productivo.
A principios de este mes llegó el momento de poner en producción las instalaciones, configuraciones y desarrollos que se habían ido realizado en el entorno de desarrollo, y claro está surgieron inquietudes tipo; ¿perderemos algo a la hora de realizar el traspaso? ¿cómo comprobaremos que todo ha sido traspasado correctamente? ¿habrá que parar el entorno productivo? ¿Cuánto tiempo deberá estar parado en caso afirmativo?.
Este post es la recopilación de las diferentes alternativas que contemplé para realizar el despliegue en producción del desarrollo en JIRA.
Buenas prácticas para facilitar los despliegues entre entornos de JIRA.
En cualquiera de los métodos que se van a enumerar a continuación es una buena práctica, a la hora de desarrollar en JIRA seguir una metodología que nos lleve a documentar las diferentes configuraciones y desarrollos que realizamos. Normalmente la documentación es uno de los entregables que menos se cuida cuando se realiza la entrega de un producto software, pero sin embargo en JIRA es una pieza esencial para entender qué se ha hecho y facilitar los despliegues y migraciones posteriores.
Otra buena práctica es contar, con un entorno de desarrollo donde personalizar las configuraciones, realizar los desarrollos y probar los plugins que vamos a llevar a producción, con un entorno pre-productivo, donde si la instalación de JIRA es crítica para el negocio, poder probar que no se rompe nada con el desarrollo que queremos llevar a producción, y con un entorno productivo que es el que finalmente da servicio al negocio.
Por supuesto, y esta va a ser una buena práctica basada en el sentido común, si se está desarrollando un plugin para JIRA, el nombre de los paquetes java debe ser propio y concluyente. Sería lioso si utilizáramos como nombre com.atlassian.jira.plugins, mucho mejor sería org.mycompany.jira.plugins.
Recopilación de diferentes métodos para estos despliegues.
Una vez terminado el desarrollo, normalmente en un entorno no productivo, el siguiente paso es ponerlo en producción. Para ello existen varios caminos de los cuales elegiremos el que mejor nos cuadre con nuestra manera de trabajar. A continuación enumero aquellos métodos que tuve en cuenta en la puesta en producción del proyecto que teníamos entre manos, y después os contaré cual elegimos y el motivo.
Método manual.
Si se ha cumplido la premisa de que el desarrollo está correctamente documentado, y tenemos un inventario claro y ordenado de los cambios que se han realizado, este método proporciona varias ventajas y algún que otro pero.
La principal ventaja es que el control y conocimiento en el despliegue es total. Paso a paso se replican los cambios realizados en desarrollo y que han llevado al buen funcionamiento en dicho entorno. Si surge algún problema, se soluciona y se procede a actualizar la documentación hasta dejarla correctamente depurada.
Este método permite que el despliegue productivo lo realice personal técnico ajeno al desarrollo, que no solo valida la documentación, si no que adicionalmente adquieren conocimiento de la instalación.
Como contra, de todos los métodos que voy a enumerar, este es con diferencia el más lento de todos ellos, pudiendo llevar horas cada implantación a producción. Además, es esencial contar con un entorno pre-productivo donde depurar la documentación y poder probar que todo funciona correctamente antes de poner el software en producción.
Método basado en herramientas out-of-the-box.
Para agilizar los despliegues de los workflows, con los que hemos personalizado nuestra instalación, podemos utilizar las herramientas de exportación que se proporciona con la instalación básica de JIRA. Estas herramientas permiten exportar los workflows en un fichero empaquetado. Este fichero empaquetado se puede incluso desplegar en el Atlassian Marketplace pasando a estar disponible para replicar en otros entornos JIRA de nuestra compañía, e incluso en entornos JIRA de otras compañías.
Ni que decir tiene que al ser un método basado en las herramientas que proporciona el propio JIRA es un método seguro y fiable, que exporta los workflows con total garantía y que cuenta con la ventaja de que al publicarse en el Atlassian Marketplace, automáticamente queda disponible para ser utilizado en otros entornos de JIRA.
Por supuesto, al automatizar parte del proceso de despliegue, éste se hace más rápido y las implantaciones duran menos que siguiendo el método manual.
Como contra decir que la exportación e importación de JIRA solo funciona con workflows, quedando fuera ventanas, plugins y otros elementos que habría que seguir exportando manualmente.
Método basado en herramientas de terceros.
Ante la inexistencia de herramientas nativas que manejen el ciclo de vida de los desarrollos y sus despliegues a diferentes entornos, terceras empresas han desarrollado herramientas que facilitan estas tareas y que ofrecen a través de plugins, normalmente de pago.
Los plugins mejor valorados en el marketplace de Atlassian son:
El plugin fue creado para automatizar la migración de las configuraciones de proyectos teniendo en cuenta todo tipo de componentes.
El plugin está creado por Botron Software, un desarrollador de plugins certificado por Atlassian con un soporte de 8 horas al día, 5 días a la semana. El plugin está soportado por el propio Atlassian.
La versión 5.1.4 del plugin es compatible con Jira Server desde la versión 6.3 hasta la versión 7.7.0.
Entre otras cosas el plugin:
Permite realizar snapshots de JIRA a nivel de Proyecto, incluso a nivel de Sistema que pueden ser desplegadas en otros servidores JIRA.
Analiza automáticamente todos los cambios y determina si existe impacto en otros proyectos publicados en el servidor JIRA destino.
El despliegue de los snapshots lleva unos pocos minutos, en vez de las horas que implica llevar a cabo todas las operaciones de un despliegue manual.
Proporciona una trazabilidad completa de las operaciones realizadas.
A día de hoy, el licenciamiento de esta herramienta es el siguiente:
10 users 10$
25 users 500$
50 users 1000$
100 users 1800$
250 users 3200$
Project configurator
El plugin fue creado para mover proyectos, o solo sus configuraciones, de una instanacia de JIRA a otra.
El plugin está creado por Adaptavist, un desarrollador de plugins certificado por Atlassian con un soporte de 8 horas al día, 5 días a la semana. El plugin está soportado por el propio Atlassian.
La versión 2.3.0J7 del plugin es compatible con Jira Server desde la versión 7.0.0 hasta la versión 7.6.3 de JIRA. Como ventaja adicional, están compatibilizando esta versión con la versión JIRA Service Desk.
Entre otras cosas el plugin:
Exportar uno o múltiples proyectoen un único fichero de exportación.
Exportar todo el proyecto o sólo las configuraciones.
Proporciona trazabilidad completa de la información exportada.
Simular como afectan los cambios de configuraciones en la instancia destino de JIRA.
A día de hoy, el licenciamiento de esta herramienta es el siguiente:
10 users 10$
25 users 125$
50 users 235$
100 users 395$
250 users 565$
La gran ventaja de utilizar cualquiera de estas herramientas es que son capaces de gestionar el despliegue de proyectos y esquemas completos, pudiendo exportar toda la estructura o solo las configuraciones. Además, proporcionan trazabilidad completa de las operaciones que se llevan a cabo, permitiendo simular la implantación y detectar antes de implantar si existe o no algún riesgo de incompatibilidad entre lo que se sube y lo que ya existe en el servidor.
Por supuesto, al realizarse de manera automática, los despliegues tardan muchísimo menos en finalizar, no por ello dejándose a un lado la seguridad de un buen despliegue.
Por contra, lo bueno cuesta dinero, y dependiendo del número de usuarios de la licencia de JIRA nos costará más o menos poder utilizarlos.
Otros métodos
Adrede dejo fuera del estudio otros métodos, como la clonación del esquema de la base de datos de desarrollo en producción, o la realización de un exportador a medida utilizando el REST API de JIRA, porque o bien no lo considero adecuado, o bien no considero que el despliegue sea tan complejo que el esfuerzo merezca la pena.
Conclusión.
La elección del método depende de varias variables:
la primera del esfuerzo y participación que se quiere tener en el despliegue
la ventana horaria que hay para realizar los despliegues
el presupuesto
Tanto si el despliegue no debe suponer un gran esfuerzo, como si la ventana horaria no es muy grande deberíamos elegir un método lo más automático posible, las herramientas de terceros es el método más rápido y más desatendido, como contra está el presupuesto del que disponemos para dedicar a los despliegues. El método manual queda relegado a aquellas personas a las que le gusta tener el control absoluto de la implantación y tienen un profundo conocimiento tanto de lo que están haciendo como de la administración de JIRA, sin importarles el tiempo que les lleva el despliegue.
En todas las empresas para las que he trabajado in-situ siempre me he encontrado un proxy para que los trabajadores accedemos a internet de manera controlada y de manera productiva. Desgraciadamente, los proxies a veces dan quebraderos de cabeza cuando las aplicaciones que usamos necesitan de una conexión con la red de redes para funcionar correctamente. GIT es una de esas aplicaciones que, por ejemplo, cuando queremos consolidar nuestro código fuente en la nube, necesita de una conexión a internet para funcionar correctamente, y si hay un proxy de por medio, necesitaremos de una configuración extra para conseguirlo.
La herramienta para configurar GIT
Antes de nada, una pequeña pincelada de la herramienta que GIT proporciona para obtener y establecer variables de configuración que controlan el funcionamiento de GIT: git config.
Se puede elegir que estas configuraciones se almacenen en tres lugares distintos, dependiendo del nivel de alcance que queremos que tengan:
/etc/gitconfig (en windows /mingw64/etc/gitconfig): Contiene configuraciones para todos los usuarios del sistema y para todos los repositorios. Para ello hay que pasar el comando –system a git config.
/.gitconfig: Contiene configuraciones específicas del usuario para todos los repositorios. Para ello hay que pasar el comando –global a git config.
/.git/config/config: Contiene configuraciones propias de cada repositorio. En este caso, no es necesario pasar comando alguno, pero hay que indicar el repositorio sobre el que se quiere aplicar la configuración.
Cada nivel sobreescribe los valores del nivel anterior, por lo que los valores particulares del repositorio tienen preferencia frente a los del usuario y estos, a su vez, tienen preferencia frente a los de sistema.
proxy.user es el usuario que tiene permiso para acceder al proxy.
proxy.pass es la password de dicho usuario
proxy.name_or_ip es el nombre DNS o la dirección IP de la máquina que hace de proxy de internet.
proxy.port es el puerto por el que se accede a comunicar con el proxy de internet.
–global, le indica a git que la configuración es propia del usuario y sirve para todos sus repositorios.
Consultar el proxy configurado en git
git config --global --get http.proxy
Borrar el proxy configurado en git.
git config --global --unset http.proxy
Conclusión
En este caso la solución es sencilla y funciona correctamente si seguimos los pasos indicados. Espero, como siempre, que esta información, aunque fácil de encontrar en la documentación oficial de GIT, sea de utilidad.
En esta entrada voy a hablar de GIT de una manera muy básica, conceptos, funcionamiento y uso práctico desde un punto de vista útil del día a día.
GIT vs Subversion
Para alguien como yo que vengo de utilizar primero CVS y después Subversion, el funcionamiento de GIT puede resultar a priori familiar, sobre todo debido a que los comandos parecen similares a los de Subversion, pero esta familiaridad puede inducir a errores a la hora de funcionar. Por tanto, es importante entender el funcionamiento de GIT para no cometer errores basados en la experiencia con otras herramientas.
La principal diferencia entre SVN y GIT es la manera de modelar el control de los ficheros fuentes. Subversion almacena la versión inicial de los datos que queremos controlar y posteriormente va almacenando los cambios realizados sobre ellos, esta información sobre los cambios se conocen como deltas. GIT sin embargo, almacena instantaneas de cada momento concreto, y para resultar óptimo si un fichero no ha cambiado se utiliza la versión guardada en la instantánea anterior.
Estructura de un respositorio GIT
Un repositorio GIT se almacena en local, no en un servidor, y la información que se almacena está compuesta por tres árboles conceptuales: el directorio de trabajo que contiene los archivos, el Index que actúa como zona intermedia y el árbol HEAD que apunta al último commit realizado.
Bondades de GIT
La mayoría de las operaciones de GIT solo necesitan archivos y recursos locales lo que proporciona más sensación de rapidez. Por ejemplo, para consultar la historia del proyecto, GIT no tiene que conectar con un servidor remoto y esperar su respuesta, si no que obtiene la información de la base de datos local. Para obtener las diferencias de un fichero con la versión de hace un mes, buscará el fichero en local y calcularás las diferencias sin tener que ir a una ubicación externa. Esto permite operar con GIT sin tener conexión efectiva con el exterior.
Descargar GIT
GIT se puede descargar desde la sección de descargas de su sitio web oficial. Existen binarios para Windows (32 y 64bits) , Mac OS X, Linux y Solaris.
Uso práctico
Creación de un repositorio nuevo
Para poner bajo el control de GIT un directorio con código fuente hay que generar un repositorio sobre él. Esto se realiza situándose en el directorio y ejecutando el siguiente comando:
git init
Este comando convierte automáticamente el directorio elegido en el (master) y crea dentro un subdirectorio .git que contiene toda la información que GIT necesita para funcionar correctamente.
Aunque se ha creado el repositorio, todavía ninguno de los fuentes están todavía bajo el control de GIT. Para ello hay que añadir los ficheros que se desean controlar al repositorio.
Conectar con un repositorio existente.
Hay ocasiones en las que se desea descargar el código fuente de un repositorio ya existente (de un master).
Para ello hay que situarse en el directorio donde se quiere tener el código fuente descargado. Para ello se ejecuta el siguiente comando:
git clone username@host:/path/to/repository
Este comando descarga el código a la carpeta desde la que se ha lanzado su ejecución. Si el (master) se encuentra en la máquina local se puede lanzar el comando omitiendo username@host:.
Si te pasa como a mí me pasa a menudo, que primero desarrollo y luego cuando me parece que la cosa merece la pena decido ponerla a buen recaudo bajo un control de fuentes, te darás cuenta que GIT, a diferencia de otros, no permite realizar la operación de clonado sobre un directorio existente (y lleno de fuentes). En este caso, los pasos a dar son los siguientes:
Realizar el clone en un directorio temporal
git clone username@host:/path/to/repository temp
Copiar el fichero .git al directorio donde queríamos clonar el repositorio originalmente.
mv temp/.git code/.git
Borrar el directorio temporal.
rm -rf temp
Añadir ficheros nuevos a un repositorio.
Para añadir ficheros de código fuente al control de GIT se realiza en dos pasos: añadir (add) y consolidar (commit).
Añadir el fichero le dice a GIT que ficheros tiene que tener en cuenta a la hora de realizar el control. Para ello se lanza el siguiente comando:
git add <filename>
Si se quieren añadir todos los ficheros de un directorio se lanza el siguiente comando:
git add .
Si se quieren añadir todos los ficheros con una extensión concreta se lanza el comando:
git add *.<extensión>
Una vez indicado qué ficheros hay que añadir al control de GIT, hay que consolidarlos.
Eliminar ficheros de un repositorio.
La eliminación de ficheros de código fuente al control de GIT también se realiza en dos pasos: eliminar (remove) y consolidar (commit).
El comando para eliminar un fichero es el siguiente:
git rm <filename>
Si lo que se quiere borrar es una carpeta con su contenido habrá que indicarle a git que el borrado es recursivo:
git rm -r <path/to/remove>
Una vez indicados los ficheros a borrar hay que consolidar este cambio en GIT.
Consolidar los cambios en el repositorio local.
Tanto si se ha añadido, como si se ha modificado o eliminado ficheros, hay que consolidar estas operaciones en el repositorio. Hasta que no se lleve a cabo la consolidación, los cambios solo estarán disponibles en nuestro área de trabajo.
Para consolidar los cambios se lanza el comando:
git commit -m "<mensaje de la consolidación>"
Consolidar los cambios en el repositorio remoto.
Una vez consolidado los cambios en el repositorio local, tal vez deseemos consolidar estas operaciones en el repositorio master. Hasta que no se lleve a cabo la consolidación, los cambios solo estarán disponibles en nuestro repositorio GIT local.
Para consolidar los cambios se lanza el comando:
git push
Generar un TAG de versión a partir de una situación concreta en el repositorio.
Una vez que se ha terminado de realizar el desarrollo y se ha decidido que el software está listo para ir a producción, se puede etiquetar el HEAD con el nombre que se estime oportuno.
Este proceso de etiquetado en GIT se conoce como TAG (también en SVN) y se lleva a cabo con el comando:
git tag <nombre-tag> <id. commit>
El nombre del TAG normalmente suele ser un número de versión, por ejemplo, 1.0, 1.0.1, 5.2.4. El identificador del commit se puede obtener con el comando git log y es un alfanumérico único que identifica el repositorio con una instantánea concreta.
En esta entrada voy a realizar una aplicación muy básica con JSF 2.x y voy a internacionalizarla, de forma que se pueda ejecutar en dos lenguajes diferentes: español e inglés.
Es conveniente si tenemos claro que la aplicación debe aceptar varios idiomas que la internacionalización la apliquemos en la fase más temprana posible. Incorporar la internacionlización cuando la aplicación ya está muy avanzada suele ser bastante más costoso que hacerlo en etapas tempranas por varios motivos, pero principalmente las diferencias que hay entre los diferentes idiomas en cuanto a decir lo mismo con más o menos palabras pueden afectar al diseño de las páginas.
Requisitos para desarrollar el ejemplo.
Para que se pueda reproducir el ejemplo y esté operativo al 100% comento qué entorno he utilizado para hacerlo funcionar.
IDE desarrollo: Eclipse 3.6 (Neon).
Máquina virtual Java: JDK 1.8.0_65.
Servidor de aplicaciones: Apache Tomcat 8.5
Ciclo de vida: Maven 3.x
Tecnología: JSF 2.2 (Java EE 7)
Recomiendo la lectura de la entrada JSF 2.x Hola Mundo pues en ella comento todos los aspectos de configuración que en esta entrada voy a dar por supuestos, como la elección de librerías, configuración de servlets, etcétera.
Módulo web de aplicación.
Este ejemplo es tan sencillo que va a contar con un único módulo; el módulo web. El módulo web genera un WAR que se despliega directamente en Apache Tomcat.
Destacar la inclusión de un parámetro de configuración que indica donde se encuentra el fichero de configuración de JSF. En este ejemplo vamos a incluir este fichero de configuración ya que va a ser necesario indicar los ficheros donde se encuentran las traducciones del idioma y el idioma por defecto de la aplicación.
El campo <locale-config> sirve para definir las configuraciones relativas a la situación geográfica, entre ellas las localizaciones permitidas <supported-locale> o la localización por defecto <default-locale>. La localización es imprescindible para internacionalizar la aplicación.
El campo <resource-bundle> es la piedra angular de la internacionalización, ya que en él se indica donde va a encontrar la aplicación los ficheros que contienen las etiquetas en sus respectivos idiomas <base-name> y el nombre de la variable que se va a utilizar para hacer referencias a ellas <var>. Así podremos encontrar en las páginas dinámicas código como el siguiente donde se hace referencia a la etiqueta i18nwelcome.saludo del grupo de recursos identificado por el nombre de variable i18n:
El fichero faces-config.xml añade un montón de posibilidades de configuración más, pero se escapan al ámbito de esta entrada. Pueden consultarse en el siguiente link.
Los ficheros de recursos para los idiomas.
Estos ficheros contienen las traducciones a diferentes idiomas de las etiquetas de la aplicación. El nombre es el indicado en el campo <base-name> al que se le concatena el lenguaje de la variable Locale. Por ejemplo, para contener las etiquetas en inglés de la aplicación, el fichero se llama i18nBasico_en.properties.
i18nwelcome.titulo = Ejemplo de internacionalización con JSF 2.x.
i18nwelcome.saludo = Internacionalización con JSF 2.x.
i18nwelcome.etiquetaIdioma = Idioma
i18nwelcome.descripcion-metodo1 = Método basado en una lista seleccionable.
i18nwelcome.descripcion-metodo2 = Método basado en imágenes.
Se puede ver que el nombre de las etiquetas es el mismo en ambos ficheros, pero el valor de las mismas está traducido al idioma que se indica en el nombre del fichero.
El Managed Bean que maneja la lógica de presentación del idioma.
Fichero: es.egv.jee6.jsf2.i18n.IdiomaBean.java
package es.egv.jee6.jsf2.i18n;
import java.io.Serializable;
import java.util.LinkedHashMap;
import java.util.Locale;
import java.util.Map;
import javax.faces.bean.ManagedBean;
import javax.faces.bean.SessionScoped;
import javax.faces.context.FacesContext;
import javax.faces.event.ValueChangeEvent;
@ManagedBean(name="idiomaBean")
@SessionScoped
public class IdiomaBean implements Serializable {
private static final long serialVersionUID = 1L;
private String codigoIdioma;
private Map<String,Object> listaIdiomas;
public IdiomaBean() {
super();
this.codigoIdioma = FacesContext.getCurrentInstance().getViewRoot().getLocale().getLanguage();
this.listaIdiomas = new LinkedHashMap<String,Object>();
this.listaIdiomas.put("Español", new Locale("es"));
this.listaIdiomas.put("Inglés", new Locale("en"));
}
public String getCodigoIdioma() {
return codigoIdioma;
}
public void setCodigoIdioma(String codigoIdioma) {
this.codigoIdioma = codigoIdioma;
}
public Map<String, Object> getListaIdiomas() {
return listaIdiomas;
}
public void doCambioIdiomaConLista(ValueChangeEvent e)
{
String newCodigoIdioma = e.getNewValue().toString();
System.out.println("newCodigoIdioma=" + newCodigoIdioma);
System.out.println("idiomaBean=" + this.toString());
//loop country map to compare the locale code
for (Map.Entry<String, Object> entry : listaIdiomas.entrySet())
{
if(entry.getValue().toString().equals(newCodigoIdioma))
{
System.out.println("Asignando nueva locale al contexto de Faces.");
FacesContext.getCurrentInstance().getViewRoot().setLocale((Locale)entry.getValue());
}
}
}
public void doCambioIdiomaConImagen(String nuevoIdioma)
{
//loop country map to compare the locale code
for (Map.Entry<String, Object> entry : listaIdiomas.entrySet())
{
if(entry.getValue().toString().equals(nuevoIdioma))
{
System.out.println("Pinchado en imagen " + nuevoIdioma + ". Asignando nueva locale al contexto de Faces");
this.codigoIdioma = nuevoIdioma;
FacesContext.getCurrentInstance().getViewRoot().setLocale((Locale)entry.getValue());
}
}
}
@Override
public String toString() {
return "IdiomaBean [codigoIdioma=" + codigoIdioma + ", listaIdiomas=" + listaIdiomas + "]";
}
}
Defino un managed bean específico para manejar el idioma. Será el encargado de conservar el idioma seleccionado por el usuario, una lista de idiomas seleccionables, y las diferentes acciones que se llevan a cabo cuando se realizan acciones relacionadas con el idioma.
@ManagedBean(name="idiomaBean")
@SessionScoped
public class IdiomaBean implements Serializable {
Este ManagedBean lo defino en el ámbito de la sesión @SessionScoped. De esta manera, el idioma queda almacenado en todas las navegaciones que realice el usuario hasta que cierre el navegador, o la sesión.
Se definen la variable codigoIdioma para contener el idioma seleccionado por el usuario y la variable listaIdiomas para contener los idiomas que van a mostrarse al usuario para proceder a la traducción de la aplicación.Se incluyen también sus getters y sus setters.
public IdiomaBean() {
super();
this.codigoIdioma = FacesContext.getCurrentInstance().getViewRoot().getLocale().getLanguage();
this.listaIdiomas = new LinkedHashMap<String,Object>();
this.listaIdiomas.put("Español", new Locale("es"));
this.listaIdiomas.put("Inglés", new Locale("en"));
}
Se incluye un constructor para rellenar el código del idioma con el idioma configurado por JSF en el arranque, que será el idioma que se ha configurado en el <default-locale> del fichero faces-config.xml, y rellenar la lista de idiomas con los idiomas válidos para la aplicación.
public void doCambioIdiomaConLista(ValueChangeEvent e)
{
String newCodigoIdioma = e.getNewValue().toString();
System.out.println("newCodigoIdioma=" + newCodigoIdioma);
System.out.println("idiomaBean=" + this.toString());
//loop country map to compare the locale code
for (Map.Entry<String, Object> entry : listaIdiomas.entrySet())
{
if(entry.getValue().toString().equals(newCodigoIdioma))
{
System.out.println("Asignando nueva locale al contexto de Faces.");
FacesContext.getCurrentInstance().getViewRoot().setLocale((Locale)entry.getValue());
}
}
}
Se añade un método para manejar el cambio del idioma cuando se seleccione un idioma de la lista.
Y, se añade un método que se ejecutará cuando se seleccione un cambio de idioma pinchando en la imágen del mismo.
public void doCambioIdiomaConImagen(String nuevoIdioma)
{
//loop country map to compare the locale code
for (Map.Entry<String, Object> entry : listaIdiomas.entrySet())
{
if(entry.getValue().toString().equals(nuevoIdioma))
{
System.out.println("Pinchado en imagen " + nuevoIdioma + ". Asignando nueva locale al contexto de Faces");
this.codigoIdioma = nuevoIdioma;
FacesContext.getCurrentInstance().getViewRoot().setLocale((Locale)entry.getValue());
}
}
}
Destacar que se ha incluido la asignación del idioma seleccionado a la variable codigoIdioma del bean para que quede guardada la sección.
this.codigoIdioma = nuevoIdioma;
Páginas web dinámicas.
El ejemplo consta de tres páginas web dinámicas: i18nwelcome.xhtml que es la página básica de bienvenida, i18nidiomametodo1.xhtml que es la página con el manejo de idioma basado en una lista seleccionable, e i18nidiomametodo2.xhtml que es la página con el manejo del idioma basado en imágenes.
Esta página muestra dos etiquetas a internacionalizar; i18nwelcome.titulo e i18nwelcome.saludo. Para mostrar correctamente el idioma se utiliza expresiones EL que son interpretadas por JSF en tiempo de ejecución.
#{i18n['i18nwelcome.titulo']}
Esta expresión indica que se va a recoger del bundle i18n la etiqueta i18nwelcome.titulo.
Por claridad, los dos métodos que se van a utilizar para la selección del idioma se han realizado en dos páginas dinámicas independientes que se incluyen en la página básica mediante la sentencia <ui:include src=»»/>.
Destacar que se muestra el botón con la bandera del idioma que no está seleccionado, para así poder cambiarlo. Para ello se utiliza el atributo rendered y expresiones EL.
En el último proyecto en el que estoy recientemente involucrado he definido un entorno de trabajo virtualizado con máquinas basadas en Windows 10 que no se incluyen en el dominio y por tanto no realizan autenticación en él; la autenticación se realiza mediante usuarios locales. Sin embargo, para salir a internet se utiliza un proxy, en el que sí es necesario autenticarse a través del dominio windows de la organización.
A priori, sobre el papel esta configuración es bastante común y no da problemas. Para abrir una URL de internet desde el navegador, inicialmente se intenta hacer login con el usuario local, al no ser usuario de dominio y no poder autenticarse en el dominio, el navegador muestra una ventana para introducir el usuario y la password correctas. Si con ese usuario y password la autenticación es correcta en el dominio, automáticamente se navega a la url exterior solicitada.
En las máquinas virtuales de los desarrolladores, con Internet Explorer no hay ningún tipo de problema, se introduce el usuario, la password y la salida a internet es automática. Con Microsoft Edge el funcionamiento es correcto también, pero con Firefox (cualquier versión, aunque concretamente estamos utilizando Firefox Developer Edition 50.0a2) empiezan los problemas ya que este navegador se bucla solicitando continuamente el usuario y la password que el proxy necesita para realizar la autenticación.
Solución
Este problema que es bastante engorroso, porque anula el funcionamiento de Firefox y lo elimina como navegador, se soluciona cambiando varias configuraciones internas de Mozilla Firefox.
Para acceder a dichas configuraciones hay que teclear la url about:config.
Es probable que si no hemos accedido antes a ésta URL, nos pida una confirmación para mostrar la página, pues modificar las configuraciones avanzadas puede ser potencialmente peligroso para el navegador.
En este caso como estamos seguros de lo que vamos a configurar pinchamos en Aceptamos el riesgo.
Estas configuraciones pueden ser encontradas mediante el campo de Busqueda. El cambio en los campos booleanos se realiza haciendo doble click sobre ellos.
Completadas las configuraciones, se cierra y vuelve a abrir el navegador, se teclea la url de internet a la que se quiere navegar, se rellena el usuario y la password (una única vez), et voila, debería mostrarse el contenido web de la URL.